ALVisualCompass¶
NAOqi Vision - Overview | API
What it does¶
ALVisualCompass is an extractor which gives the current rotation angles of the robot compared to a given reference image along the Y and Z axis.
The module gives the rotation of the FRAME_ROBOT reference, so the whole body of the robot and not only its head. This means that if the robot stays standing but moves its head, the deviation angles will not change.
When to use it¶
ALVisualCompass may be used to get the robot’s rotation around the Z axis independently of the measure of the same angle theta by the robot’s odometry. As a consequence, it also provides a public method to make the robot walk with a controlled deviation.
Note
ALVisualCompass only works on a real robot, since it retrieves the images from its cameras.
How it works¶
You can find an example on how to use ALVisualCompass here.
General principle¶
The module first extracts keypoints from the reference image, and the current camera position and stores them.
When the module is running, it then extracts keypoints from the current image, and tries to match them with the ones from the reference image. It then computes the global deviation of all keypoints which are in both reference and current images, and deduces the rotation between the two. It then takes into account the current camera position, and by comparing it to the reference position, determines the deviation of the robot.

Example of keypoints matching allowing to compute the compass deviation
On this image, the top image is the reference image, and the bottom the current one. Each circle represents a keypoint, and the linked keypoints correspond to the pairs of matched keypoints. The green pairs are model inliers, which means they are used to compute the deviation, the red ones are outliers, so they are not taken into account because they are too different from the others.
This image shows that mismatches can be eliminated as outliers, and that the global deviation is easily visible (here, the current image is to the left of the first one).
Keypoints tracking¶
Features of interest¶
The keypoints have to be robust to scale changes (since the robot can be moving). The keypoints extracted are FAST keypoints (see E. Rosten’s page and OpenCV documentation) on three octaves to support several scales.
Global deviation¶
Each pair of point will have its own deviation. To compute the one that fits best with the matched points while still being robust to outliers (wrong matching for example), the module uses a RANSAC method to get the rotation on Y and Z axis.
Compass corrected navigation¶
Thanks to the results of the global deviation part, the trajectory can be corrected
with the ALVisualCompassProxy::moveTo function. This function
is designed to reach a target position (x, y, theta) with a good precision. This
function process in three parts. First, the robot turns towards the target position (x,y).
Then, the robot moves until the target position. And finally, the robot turns towards the
target orientation. It’s decomposed in this way, because it is easier to correct pure
rotation and translation with vision when no depth information is available.
In this mode, the robot automatically takes and refreshes its reference. It is advised not to change the reference during this phase.
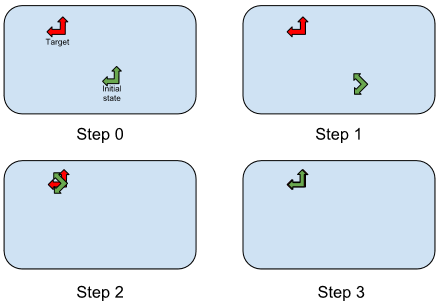
MoveTo Steps.
Performances and limitations¶
Reference visibility¶
The algorithm is dependent on the fact that at least part of the reference image is visible while the compass is running. If the visual reference is out of the robot’s field of view, the compass will not be able to give any information.
In that case, ALVisualCompass switches to a regular odometry to finish the move.
Quality indicators¶
- Number of matches: The more points that are matched, the better the deviation computation.
- Percentage of inliers: The percentage of inliers for the model (the keypoints that are not absurdly matched) is also important: if it is under 50%, then the RANSAC computation is not significant.
Both these values are accessible here: ALVisualCompassProxy::getMatchingQuality.
CPU usage and refresh period¶
The keypoint extraction and matching is quite CPU consuming.
It is recommended to adapt the refresh period to your needs to avoid unnecessary computations.
Image resolution¶
By default, ALVisualCompass uses the lowest resolution possible to save computational power (QQVGA or 160x120 resolution). However, it is possible to raise the resolution, to improve the precision of the compass but at the cost of a slightly slower processing.
To adjust the image resolution, use ALVisualCompassProxy::setResolution
inherited from ALVisionExtractor::setResolution.
It is possible, but not recommended, to change the image resolution on the
fly while the extractor is running: in that case, the current image will be scaled
to match the reference resolution, which will cost some computational power,
until the reference has been refreshed.
Image blur¶
When the robot is walking, the image can be relatively blurred because the head is oscillating. To compensate for that, ALVisualCompass compares the sharpness of the current image to the one of the reference image: if the current image is significantly less sharp than the reference, then the image is skipped.
This saves computational power, since images which are too blurry are not processed. If you see that the associated events are refreshed less often, this means that the images are too blurry: this can be fixed by slowing down the walk and / or the head moves.